搜索到
39
篇与
的结果
-
 从零起步,Ubuntu环境搭建Typecho个人博客的保姆级教程 一、确认服务器环境是否满足要求根据Typecho官网要求,运行需要基础环境支持,先检查是否安装以下组件:Web 服务器:Nginx 或 Apache(推荐 Nginx,更轻量)。PHP:5.6 及以上版本(推荐 7.2+),并需启用必要扩展(如 pdo_mysql、mbstring、json、gd 等)。数据库:MySQL 或 MariaDB(用于存储博客数据)。 官网链接: https://typecho.org/二、快速安装基础环境默认大家没有任何环境,从零开始# 安装 Nginx、PHP、MySQL sudo apt update sudo apt install nginx php php-fpm php-mysql php-mbstring php-gd php-json mysql-server三、下载并上传至服务器根据官网下载链接,将下载的zip压缩包,放在服务器自定义的目录下,以/usr/local/typecho 为例四、配置 Web 服务器(以 Nginx 为例)Web 服务器需要将访问请求指向 Typecho 的安装目录(/usr/local/typecho),并处理 PHP 解析。1、创建 Nginx 配置文件sudo nano /etc/nginx/sites-available/typecho # 新建配置文件2、写入配置内容根据你的服务器 IP 或域名修改以下内容(假设用 IP 访问,或已解析域名):server { listen 80; # 监听 80 端口(HTTP) server_name your_domain.com; # 替换为你的域名或服务器 IP(如 1.2.3.4) # 网站根目录指向 Typecho 解压目录 root /usr/local/typecho; index index.php index.html; # 默认索引文件 # 关键:Typecho 伪静态规则(必须添加) location / { # 如果请求的文件或目录不存在,将请求转发给 index.php 处理 if (!-e $request_filename) { rewrite ^(.*)$ /index.php?$1 last; } } # PHP 解析配置(保持不变) location ~ \.php$ { fastcgi_pass unix:/run/php/php8.1-fpm.sock; # 替换为你的 PHP 版本 fastcgi_index index.php; include fastcgi_params; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; } # 禁止访问隐藏文件(保持不变) location ~ /\. { deny all; access_log off; log_not_found off; } # 静态资源缓存(保持不变) location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ { expires 30d; add_header Cache-Control "public, max-age=2592000"; } # 日志配置(可选) access_log /var/log/nginx/typecho_access.log; error_log /var/log/nginx/typecho_error.log; }注意:fastcgi_pass 中的 PHP 版本需与你安装的一致(可通过 ls /run/php/ 查看实际 sock 文件名)。3、启用配置并重启 Nginxsudo ln -s /etc/nginx/sites-available/typecho /etc/nginx/sites-enabled/ # 启用站点 sudo nginx -t # 检查配置是否有误 sudo systemctl restart nginx # 重启 Nginx五、设置 Typecho 目录权限Typecho 需要对部分目录有写入权限(如配置文件、缓存、上传目录),否则安装时会提示 “无法写入配置文件”。执行以下命令修改权限:# 递归设置目录所有者为 Web 服务器用户(Nginx 通常用 www-data) sudo chown -R www-data:www-data /usr/local/typecho # 确保关键目录可写(可选,根据实际提示调整) sudo chmod -R 755 /usr/local/typecho/usr # 上传和缓存目录 sudo chmod 755 /usr/local/typecho # 根目录(确保能生成 config.inc.php)六、准备数据库Typecho 需要数据库存储文章、用户等数据,需提前创建数据库和用户。1、登录mysqlsudo mysql -u root -p # 输入 root 密码(首次安装可能无密码,直接回车)2、执行sql命令创建数据库和用户-- 创建数据库(名称自定义,如 typecho_db) CREATE DATABASE typecho_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; -- 创建数据库用户(用户名和密码自定义,如 typecho_user / your_password) CREATE USER 'typecho_user'@'localhost' IDENTIFIED BY 'your_password'; -- 授权用户访问数据库 GRANT ALL PRIVILEGES ON typecho_db.* TO 'typecho_user'@'localhost'; -- 刷新权限 FLUSH PRIVILEGES; -- 退出 MySQL exit;七、通过浏览器访问并完成安装打开本地电脑的浏览器,输入服务器的 IP 地址 或 域名(如 http://1.2.3.4 或 http://your_domain.com)。如果配置正确,会看到 Typecho 的安装向导页面。
从零起步,Ubuntu环境搭建Typecho个人博客的保姆级教程 一、确认服务器环境是否满足要求根据Typecho官网要求,运行需要基础环境支持,先检查是否安装以下组件:Web 服务器:Nginx 或 Apache(推荐 Nginx,更轻量)。PHP:5.6 及以上版本(推荐 7.2+),并需启用必要扩展(如 pdo_mysql、mbstring、json、gd 等)。数据库:MySQL 或 MariaDB(用于存储博客数据)。 官网链接: https://typecho.org/二、快速安装基础环境默认大家没有任何环境,从零开始# 安装 Nginx、PHP、MySQL sudo apt update sudo apt install nginx php php-fpm php-mysql php-mbstring php-gd php-json mysql-server三、下载并上传至服务器根据官网下载链接,将下载的zip压缩包,放在服务器自定义的目录下,以/usr/local/typecho 为例四、配置 Web 服务器(以 Nginx 为例)Web 服务器需要将访问请求指向 Typecho 的安装目录(/usr/local/typecho),并处理 PHP 解析。1、创建 Nginx 配置文件sudo nano /etc/nginx/sites-available/typecho # 新建配置文件2、写入配置内容根据你的服务器 IP 或域名修改以下内容(假设用 IP 访问,或已解析域名):server { listen 80; # 监听 80 端口(HTTP) server_name your_domain.com; # 替换为你的域名或服务器 IP(如 1.2.3.4) # 网站根目录指向 Typecho 解压目录 root /usr/local/typecho; index index.php index.html; # 默认索引文件 # 关键:Typecho 伪静态规则(必须添加) location / { # 如果请求的文件或目录不存在,将请求转发给 index.php 处理 if (!-e $request_filename) { rewrite ^(.*)$ /index.php?$1 last; } } # PHP 解析配置(保持不变) location ~ \.php$ { fastcgi_pass unix:/run/php/php8.1-fpm.sock; # 替换为你的 PHP 版本 fastcgi_index index.php; include fastcgi_params; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; } # 禁止访问隐藏文件(保持不变) location ~ /\. { deny all; access_log off; log_not_found off; } # 静态资源缓存(保持不变) location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ { expires 30d; add_header Cache-Control "public, max-age=2592000"; } # 日志配置(可选) access_log /var/log/nginx/typecho_access.log; error_log /var/log/nginx/typecho_error.log; }注意:fastcgi_pass 中的 PHP 版本需与你安装的一致(可通过 ls /run/php/ 查看实际 sock 文件名)。3、启用配置并重启 Nginxsudo ln -s /etc/nginx/sites-available/typecho /etc/nginx/sites-enabled/ # 启用站点 sudo nginx -t # 检查配置是否有误 sudo systemctl restart nginx # 重启 Nginx五、设置 Typecho 目录权限Typecho 需要对部分目录有写入权限(如配置文件、缓存、上传目录),否则安装时会提示 “无法写入配置文件”。执行以下命令修改权限:# 递归设置目录所有者为 Web 服务器用户(Nginx 通常用 www-data) sudo chown -R www-data:www-data /usr/local/typecho # 确保关键目录可写(可选,根据实际提示调整) sudo chmod -R 755 /usr/local/typecho/usr # 上传和缓存目录 sudo chmod 755 /usr/local/typecho # 根目录(确保能生成 config.inc.php)六、准备数据库Typecho 需要数据库存储文章、用户等数据,需提前创建数据库和用户。1、登录mysqlsudo mysql -u root -p # 输入 root 密码(首次安装可能无密码,直接回车)2、执行sql命令创建数据库和用户-- 创建数据库(名称自定义,如 typecho_db) CREATE DATABASE typecho_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; -- 创建数据库用户(用户名和密码自定义,如 typecho_user / your_password) CREATE USER 'typecho_user'@'localhost' IDENTIFIED BY 'your_password'; -- 授权用户访问数据库 GRANT ALL PRIVILEGES ON typecho_db.* TO 'typecho_user'@'localhost'; -- 刷新权限 FLUSH PRIVILEGES; -- 退出 MySQL exit;七、通过浏览器访问并完成安装打开本地电脑的浏览器,输入服务器的 IP 地址 或 域名(如 http://1.2.3.4 或 http://your_domain.com)。如果配置正确,会看到 Typecho 的安装向导页面。 -
在 Ubuntu 环境下安装与配置 Nginx 的完整指南 Nginx简介 Nginx是一款高性能的开源 Web 服务器、反向代理服务器、负载均衡器和 HTTP 缓存工具。它由俄罗斯程序员伊戈尔・赛索耶夫(Igor Sysoev)于 2004 年首次公开发布,最初设计的目标是解决高并发场景下的性能瓶颈,如今已成为全球最流行的服务器软件之一,被 Netflix、Airbnb、GitHub、腾讯、阿里等众多大型企业广泛使用。本文将详细介绍如何在 Ubuntu 系统中安装、配置并优化 Nginx,适合初学者入门参考。一、安装 NginxUbuntu 的官方软件仓库中已经包含了 Nginx,我们可以通过 APT 包管理器轻松安装。更新系统包列表首先确保系统包列表是最新的:sudo apt update安装 Nginx执行以下命令安装 Nginx:sudo apt install nginx验证安装是否成功安装完成后,Nginx 会自动启动。可以通过以下命令检查其运行状态:sudo systemctl status nginx如果看到 "active (running)" 字样,说明 Nginx 已经成功启动。配置防火墙 4.1 如果你的 Ubuntu 系统启用了 UFW 防火墙,需要允许 HTTP(80 端口)和 HTTPS(443 端口)流量:sudo ufw allow 'Nginx Full'可以通过以下命令验证防火墙规则:sudo ufw status 4.2 如果你跟我一样,使用的是云服务器,那么只需要在安全组中开放80端口即可二、Nginx的基本操作掌握以下基本命令可以帮助你管理 Nginx 服务:启动 Nginx:sudo systemctl start nginx停止 Nginx:sudo systemctl stop nginx重启 Nginx:sudo systemctl restart nginx重新加载配置(不中断服务):sudo systemctl reload nginx设置开机自启动:sudo systemctl enable nginx禁止开机自启动:sudo systemctl disable nginx三、Nginx 的配置文件结构Nginx 的配置文件位于/etc/nginx目录下,主要文件和目录包括:/etc/nginx/nginx.conf:主配置文件/etc/nginx/sites-available/:存储所有网站的配置文件/etc/nginx/sites-enabled/:存储启用的网站配置(通常是指向 sites-available 目录的软链接)/etc/nginx/conf.d/:可以存放额外的配置片段/etc/nginx/mime.types:定义 MIME 类型这种结构允许我们为每个网站创建独立的配置文件,便于管理。四、配置一个基本的 Web 站点下面我们创建一个简单的 Web 站点配置:创建网站目录首先为网站创建一个目录,并设置适当的权限:sudo mkdir -p /var/www/example.com/html sudo chown -R $USER:$USER /var/www/example.com/html sudo chmod -R 755 /var/www创建测试页面在网站目录下创建一个简单的 HTML 文件:nano /var/www/example.com/html/index.html添加以下内容:预览 <!DOCTYPE html> <html> <head> <title>Welcome to Example.com!</title> </head> <body> <h1>Success! The example.com server block is working!</h1> </body> </html>保存并关闭文件。创建服务器配置文件在sites-available目录下创建一个新的配置文件:sudo nano /etc/nginx/sites-available/example.com添加以下配置:server { listen 80; listen [::]:80; root /var/www/example.com/html; index index.html index.htm index.nginx-debian.html; server_name example.com www.example.com; # 替换为你的域名或服务器 IP(如 1.2.3.4) location / { try_files $uri $uri/ =404; } }这个配置指定了:监听 80 端口(HTTP)网站文件根目录默认索引文件服务器域名基本的请求处理规则启用站点配置通过创建软链接将配置文件链接到sites-enabled目录:sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/检查配置文件语法在应用配置之前,先检查语法是否正确:sudo nginx -t如果输出 "nginx: configuration file /etc/nginx/nginx.conf test is successful",说明配置没有问题。重新加载 Nginx使配置生效:sudo systemctl reload nginx测试网站如果你的域名已经解析到服务器 IP,现在可以通过浏览器访问http://example.com来查看效果。如果没有域名,可以修改本地hosts文件进行测试。五、注意如果访问80端口,显示Apache2默认页面,说明80端口被Apache服务器占用了,可以通过一下命令停止Apache服务器sudo systemctl stop apache2再次访问就可以成功访问到我们部署的页面了
-
自己动手写 Java 虚拟机笔记 - 第十部分:异常处理机制实现(系列终章) 前言在前一章中,我们实现了本地方法调用与反射机制,让 JVM 具备了与底层交互和动态访问类信息的能力。本章将聚焦 JVM 的 异常处理机制—— 这是保障程序健壮性的核心功能。Java 异常分为 Checked 异常和 Unchecked 异常,通过 throw 关键字抛出,依赖异常处理表和 athrow 指令实现捕获与处理。本章将完整实现异常的抛出、捕获逻辑,以及堆栈跟踪功能,并通过测试验证异常处理的正确性。作为系列笔记的终章,本章结尾还将对整个 JVM 实现之旅进行总结。参考资料《自己动手写 Java 虚拟机》—— 张秀宏开发环境工具 / 环境版本说明操作系统MacOS 15.5基于 Intel/Apple Silicon 均可JDK1.8用于字节码分析和测试Go 语言1.23.10项目开发主语言第十章:异常处理机制实现异常处理是 Java 语言的重要特性,允许程序在运行时捕获并处理错误,而非直接崩溃。JVM 通过异常处理表记录捕获逻辑,通过 athrow 指令抛出异常,并在栈中查找合适的处理程序。本章将实现这一完整流程。一、异常概述:类型与继承关系Java 中的所有异常都继承自 java.lang.Throwable,按是否必须捕获分为两类:异常类型定义示例Checked 异常非 RuntimeException 和 Error 的子类,必须显式捕获或声明抛出IOException、ClassNotFoundExceptionUnchecked 异常包括 RuntimeException 及其子类(运行时异常)和 Error 及其子类(错误),无需显式捕获NullPointerException、OutOfMemoryError继承关系核心:java.lang.Object └── java.lang.Throwable ├── java.lang.Error(错误,如 StackOverflowError) └── java.lang.Exception(异常) ├── Checked 异常(如 IOException) └── java.lang.RuntimeException(运行时异常,Unchecked)二、异常抛出:throw 关键字与 athrow 指令在 Java 代码中,通过 throw 关键字抛出异常,对应字节码中的 athrow 指令,负责将异常对象从操作数栈弹出并触发异常处理流程。1. athrow 指令的核心逻辑athrow 指令的执行流程:从操作数栈弹出异常对象引用(必须是非 null 的 Throwable 实例);遍历当前线程的栈帧,在每个方法的异常处理表中查找匹配的异常处理程序;找到处理程序后,清空当前栈帧的操作数栈,将异常对象推入栈顶,跳转到处理程序执行;若遍历所有栈帧仍未找到处理程序,则终止线程并输出堆栈跟踪。// ATHROW 异常抛出指令 type ATHROW struct { base.NoOperandsInstruction } func (a *ATHROW) Execute(frame *rtda.Frame) { // 1. 从操作数栈弹出异常对象 ex := frame.OperandStack().PopRef() if ex == nil { panic("java.lang.NullPointerException") // 不能抛出 null } thread := frame.Thread() // 2. 查找异常处理程序 if !findAndGotoExceptionHandler(thread, ex) { // 3. 未找到处理程序,输出堆栈并终止线程 handleUncaughtException(thread, ex) } }三、异常处理表:捕获逻辑的存储结构每个方法的 Code 属性中包含异常处理表(exception_table),记录该方法中异常捕获的范围、类型和处理程序位置,是异常捕获的核心依据。1. 异常处理表的结构// ExceptionHandler 异常处理表中的一项 type ExceptionHandler struct { startPc int // 异常监控的起始 PC 地址(包含) endPc int // 异常监控的结束 PC 地址(不包含) handlerPc int // 异常处理程序的 PC 地址(跳转目标) catchType *ClassRef // 捕获的异常类型(null 表示捕获所有异常,对应 catch (Throwable)) } // ExceptionTable 异常处理表(由多个 ExceptionHandler 组成) type ExceptionTable []*ExceptionHandler字段说明:startPc 和 endPc:定义监控的代码范围([startPc, endPc)),该范围内抛出的异常会被当前处理程序监控;handlerPc:当异常被捕获时,程序计数器跳转至此地址执行处理逻辑;catchType:指定捕获的异常类型(通过常量池中的类符号引用),null 表示捕获所有异常(对应 catch (Throwable))。2. 异常处理程序的查找逻辑当异常抛出后,JVM 需要在当前方法的异常处理表中查找最合适的处理程序:// findExceptionHandler 查找匹配的异常处理程序 func (t ExceptionTable) findExceptionHandler(exClass *Class, pc int) *ExceptionHandler { for _, handler := range t { // 1. 检查当前 PC 是否在监控范围内([startPc, endPc)) if pc >= handler.startPc && pc < handler.endPc { // 2. 若捕获所有异常(catchType 为 null),直接返回 if handler.catchType == nil { return handler } // 3. 解析捕获的异常类型,检查是否与抛出的异常兼容 catchClass := handler.catchType.ResolveClass() if catchClass == exClass || exClass.IsSubClassOf(catchClass) { // 异常类型匹配(抛出的异常是捕获类型或其子类) return handler } } } return nil // 未找到匹配的处理程序 }匹配规则:优先匹配范围包含当前 PC 且异常类型兼容的处理程序;若存在多个匹配的处理程序,按在异常处理表中的顺序优先选择第一个。四、异常处理流程:从抛出到捕获异常处理的完整流程涉及栈帧遍历、处理程序查找和流程跳转,确保异常被正确捕获或向上传播。1. 查找并执行异常处理程序// findAndGotoExceptionHandler 在栈中查找异常处理程序并跳转 func findAndGotoExceptionHandler(thread *rtda.Thread, ex *heap.Object) bool { for { // 1. 获取当前栈顶栈帧 frame := thread.CurrentFrame() // 当前指令的 PC(抛出异常的位置) pc := frame.NextPC() - 1 // 2. 在当前方法的异常处理表中查找处理程序 handler := frame.Method().ExceptionTable().findExceptionHandler(ex.Class(), pc) if handler != nil { // 3. 找到处理程序:清空操作数栈,推送异常对象,跳转执行 stack := frame.OperandStack() stack.Clear() stack.PushRef(ex) frame.SetNextPC(handler.handlerPc) return true } // 4. 未找到,弹出当前栈帧,继续在调用栈中查找 thread.PopFrame() // 5. 若栈为空,说明未找到任何处理程序 if thread.IsStackEmpty() { break } } return false }流程说明:从抛出异常的方法开始,逐层遍历调用栈(弹出栈帧),在每个方法的异常处理表中查找匹配的处理程序;找到后,清空当前栈帧的操作数栈,将异常对象推入栈顶,设置程序计数器为 handlerPc 执行处理逻辑;若遍历所有栈帧仍未找到处理程序,则该异常为 “未捕获异常”,触发线程终止。五、堆栈跟踪:fillInStackTrace 本地方法当异常未被捕获时,JVM 需要输出堆栈跟踪信息(包含异常类型、消息和调用栈),帮助定位问题。这一功能通过 Throwable.fillInStackTrace() 本地方法实现。1. 堆栈跟踪元素的结构堆栈跟踪由多个 StackTraceElement 组成,每个元素记录调用栈中的一个方法信息:// StackTraceElement 堆栈跟踪元素 type StackTraceElement struct { fileName string // 文件名(如 "ParseIntTest.java") className string // 类名(如 "ParseIntTest") methodName string // 方法名(如 "bar") lineNumber int // 行号(-1 表示未知) }2. fillInStackTrace 实现该方法填充异常的堆栈信息,记录从异常抛出点到线程启动的完整调用栈:// 注册本地方法:java/lang/Throwable.fillInStackTrace() func init() { native.Register("java/lang/Throwable", "fillInStackTrace", "(I)Ljava/lang/Throwable;", fillInStackTrace) } // fillInStackTrace 填充异常的堆栈跟踪信息 func fillInStackTrace(frame *rtda.Frame) { this := frame.LocalVars().GetThis() // 获取 Throwable 实例 // 从当前线程的栈帧中收集堆栈信息 stacks := collectStackTraceElements(frame.Thread(), this) // 将堆栈信息存储到异常对象中(通过 extra 字段) this.SetExtra(stacks) frame.OperandStack().PushRef(this) // 返回异常对象本身 } // collectStackTraceElements 收集堆栈跟踪元素 func collectStackTraceElements(thread *rtda.Thread, ex *heap.Object) []*StackTraceElement { var elements []*StackTraceElement // 遍历线程的栈帧(跳过 fillInStackTrace 方法本身的栈帧) for frame := thread.CurrentFrame().Lower(); frame != nil; frame = frame.Lower() { method := frame.Method() class := method.Class() // 创建堆栈元素:包含类名、方法名、文件名和行号 element := &StackTraceElement{ className: class.JavaName(), methodName: method.Name(), fileName: class.SourceFile(), // 从类的 SourceFile 属性获取文件名 lineNumber: method.GetLineNumber(frame.NextPC() - 1), // 获取当前 PC 对应的行号 } elements = append(elements, element) } return elements }功能:通过遍历线程的栈帧,收集每个方法的类名、方法名、文件名和行号,最终存储到异常对象中,为后续打印堆栈跟踪提供数据。六、测试:异常处理全流程验证通过 ParseIntTest 测试类验证异常的抛出、捕获和堆栈跟踪功能:1. 测试代码public class ParseIntTest { public static void main(String[] args) { foo(args); // 调用 foo 方法 } private static void foo(String[] args) { try { bar(args); // 调用 bar 方法,可能抛出异常 } catch (NumberFormatException e) { // 捕获数字格式化异常 System.out.println("捕获 NumberFormatException:" + e.getMessage()); } } private static void bar(String[] args) { if (args.length == 0) { // 若没有参数,抛出索引越界异常 throw new IndexOutOfBoundsException("没有输入参数!"); } // 尝试将参数转换为整数(可能抛出 NumberFormatException) int x = Integer.parseInt(args[0]); System.out.println("解析结果:" + x); } }2. 测试场景与结果场景 1:无参数运行(java ParseIntTest)→ bar 方法抛出 IndexOutOfBoundsException,未被 foo 的 NumberFormatException 捕获,向上传播至 main 方法,最终输出堆栈跟踪。场景 2:参数为非数字(java ParseIntTest abc)→ Integer.parseInt 抛出 NumberFormatException,被 foo 的 catch 块捕获并处理。测试结果:两种场景均按预期执行,异常捕获逻辑和堆栈输出正确。系列总结:自己动手写 JVM 的旅程从第一部分的命令行工具到本章的异常处理,我们完成了一个简易 JVM 的核心功能实现。回顾整个系列,我们走过了以下关键旅程:1. 基础搭建(第一、二章)实现命令行参数解析,作为 JVM 的入口;设计类路径查找逻辑,支持从 JAR 包、目录加载 Class 文件。2. 类加载与解析(第三、六章)解析 Class 文件结构,提取魔数、版本号、常量池、字段、方法等信息;实现方法区存储类元信息,通过类加载器完成 “加载→链接→初始化” 流程;解析符号引用为直接引用,建立类、字段、方法的运行时关联。3. 运行时数据区(第四、五章)实现线程、虚拟机栈、栈帧、局部变量表、操作数栈等核心结构;设计指令集和解释器,支持常量加载、算术运算、控制转移等基础指令;实现方法调用与返回机制,支持静态绑定和动态绑定(多态)。4. 复杂数据结构(第七、八章)实现数组的动态创建和操作指令,支持基本类型和引用类型数组;通过字符串池实现字符串常量的共享,支持字符串拼接和 intern 机制。5. 扩展能力(第九、十章)设计本地方法注册与调用框架,实现反射核心功能和类库依赖的本地方法;完整实现异常处理机制,支持异常抛出、捕获和堆栈跟踪。收获与展望通过亲手实现 JVM,我们深入理解了 “Write once, run anywhere” 的底层逻辑:从 Class 文件的二进制结构到指令执行的每一个细节,从内存管理到异常处理,每一部分都是对计算机体系结构和面向对象思想的深度实践。这个简易 JVM 仍有许多可扩展之处(如 JIT 编译、垃圾回收、并发支持等),但已覆盖核心功能,足以执行简单的 Java 程序。希望这份笔记能为同样对 JVM 原理感兴趣的开发者提供参考,让我们在探索技术底层的道路上继续前行。源码地址:https://github.com/Jucunqi/jvmgo.git
-
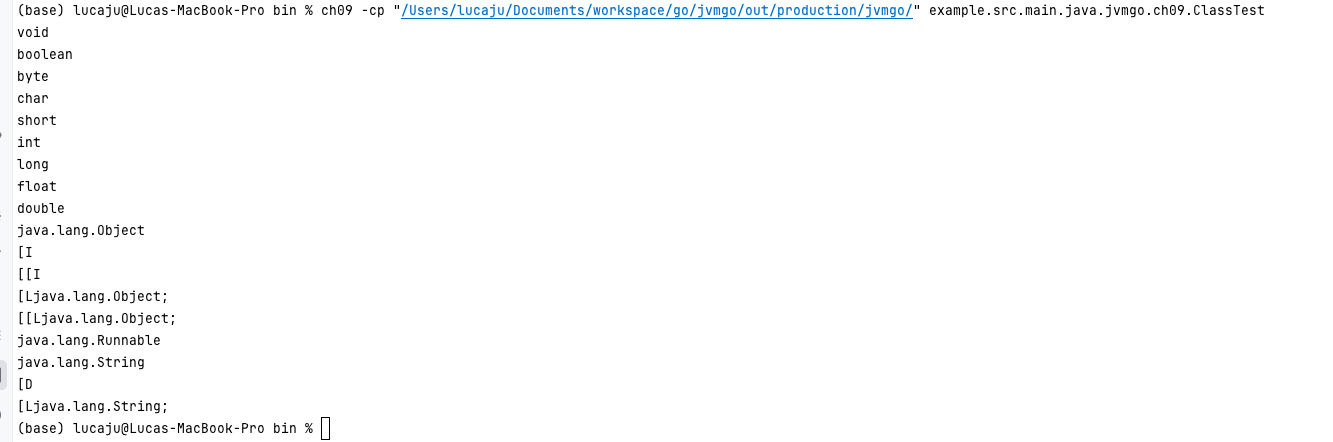
自己动手写 Java 虚拟机笔记 - 第九部分:本地方法调用与反射机制实现 前言在前一章中,我们实现了数组和字符串的核心机制,完善了 JVM 对复杂数据结构的支持。本章将聚焦 本地方法调用 与反射机制 —— 本地方法(native 方法)是 Java 与底层系统交互的桥梁(如调用操作系统 API、硬件驱动等),而反射机制则依赖本地方法实现类信息的动态访问(如动态获取类结构、调用方法)。本章将通过 Go 语言模拟本地方法的注册、调用逻辑,实现反射的核心功能,并验证关键场景(如字符串拼接、类信息获取),让 JVM 具备与底层交互和动态操作类的能力。参考资料《自己动手写 Java 虚拟机》—— 张秀宏开发环境工具 / 环境版本说明操作系统MacOS 15.5基于 Intel/Apple Silicon 均可JDK1.8用于字节码分析和测试Go 语言1.23.10项目开发主语言第九章:本地方法调用与反射机制本地方法是 Java 语言扩展能力的关键,允许开发者通过其他语言(如 C/C++)实现底层功能;反射则基于本地方法实现类信息的动态访问。本章将从本地方法的注册、调用逻辑入手,逐步实现反射机制,并验证核心场景的正确性。一、本地方法基础:注册与调用机制本地方法(native 方法)没有 Java 字节码实现,需通过外部语言实现并注册到 JVM 中。JVM 需提供注册机制和调用逻辑,确保能正确找到并执行本地方法。1. 本地方法注册:建立方法映射表本地方法通过 “类名 + 方法名 + 方法描述符” 唯一标识,使用 map 存储方法映射关系(key 为标识,value 为 Go 实现的函数)。// NativeMethod 定义本地方法的函数类型(接收栈帧,无返回值) type NativeMethod func(frame *rtda.Frame) // registry 存储本地方法映射:key 为 "类名~方法名~描述符",value 为本地方法实现 var registry = map[string]NativeMethod{} // Register 注册本地方法 func Register(className string, methodName string, methodDescriptor string, method NativeMethod) { key := className + "~" + methodName + "~" + methodDescriptor registry[key] = method }key 设计逻辑:类名、方法名、描述符共同构成唯一标识,避免不同类中同名方法的冲突(如 java/lang/System.arraycopy 与 java/util/Arrays.arraycopy 需区分)。示例:java/lang/System~arraycopy~(Ljava/lang/Object;ILjava/lang/Object;II)V 标识 System.arraycopy 方法。2. 本地方法调用:从字节码到本地实现JVM 通过 invokenative 指令调用本地方法,核心流程为:解析方法标识→查找本地实现→执行本地函数。(1)注入本地方法的 “伪字节码”本地方法无 Code 属性,需为其注入最小化字节码(用于解释器流程兼容):// injectCodeAttribute 为本地方法注入伪 Code 属性 func (m *Method) injectCodeAttribute(returnType string) { m.maxStack = 4 // 操作数栈默认深度 m.maxLocals = m.argSlotCount // 局部变量表大小=参数槽数 // 根据返回类型生成伪字节码(首字节 0xFE 标识本地方法,第二字节为返回指令) switch returnType[0] { case 'V': // void 返回 m.code = []byte{0xfe, 0xb1} // 0xFE=本地方法标识,0xB1=return 指令 case 'D': // double 返回 m.code = []byte{0xfe, 0xaf} // 0xAF=dreturn 指令 case 'F': // float 返回 m.code = []byte{0xfe, 0xae} // 0xAE=freturn 指令 case 'J': // long 返回 m.code = []byte{0xfe, 0xad} // 0xAD=lreturn 指令 case 'L', '[': // 引用类型返回 m.code = []byte{0xfe, 0xb0} // 0xB0=areturn 指令 default: // 基本类型(int/short等)返回 m.code = []byte{0xfe, 0xac} // 0xAC=ireturn 指令 } }设计目的:确保解释器能正常解析方法结构,通过 0xFE 标识触发本地方法调用逻辑。(2)invokenative 指令执行逻辑// INVOKE_NATIVE 调用本地方法的指令 type INVOKE_NATIVE struct { base.NoOperandsInstruction } func (i *INVOKE_NATIVE) Execute(frame *rtda.Frame) { method := frame.Method() className := method.Class().Name() methodName := method.Name() descriptor := method.Descriptor() // 查找本地方法实现 nativeMethod := native.FindNativeMethod(className, methodName, descriptor) if nativeMethod == nil { // 未找到本地方法时抛出异常 panic("java.lang.UnsatisfiedLinkError: " + className + "." + methodName + descriptor) } // 执行本地方法 nativeMethod(frame) } // FindNativeMethod 从注册表查找本地方法 func FindNativeMethod(className, methodName, descriptor string) NativeMethod { key := className + "~" + methodName + "~" + descriptor if method, ok := registry[key]; ok { return method } // 特殊处理:对未实现的 native 方法返回默认实现(如 Object.registerNatives) if methodName == "registerNatives" && descriptor == "()V" { return func(frame *rtda.Frame) {} // 空实现 } return nil }调用流程:从当前栈帧获取方法的类名、方法名、描述符;生成 key 并查找本地方法实现;执行找到的本地函数(传入栈帧,操作局部变量和操作数栈)。二、反射机制实现:基于本地方法的动态类访问反射允许程序在运行时动态获取类信息(如类名、方法、字段)并操作,其核心依赖 java/lang/Class 类(类对象)和相关本地方法。1. 类对象(java/lang/Class 实例)的绑定每个类在 JVM 中对应唯一的 Class 实例(类对象),存储类的元信息,是反射的入口。// Class 结构体新增类对象字段 type Class struct { // ... 原有字段 ... jClass *Object // 对应的 java/lang/Class 实例(类对象) } // 类加载时绑定类对象 func (c *ClassLoader) LoadClass(name string) *Class { // ... 原有加载逻辑 ... // 绑定类对象:当 java/lang/Class 类已加载时 if jlClassClass, ok := c.classMap["java/lang/Class"]; ok { class.jClass = jlClassClass.NewObject() // 创建 Class 实例 class.jClass.extra = class // 关联到当前类(通过 extra 字段存储元信息) } return class }类对象的作用:作为反射的入口(如 obj.getClass() 返回类对象);存储类的元信息(通过 extra 字段关联到 JVM 内部的 Class 结构体)。2. 核心反射本地方法实现反射的关键操作(如获取类名、获取类对象)依赖本地方法实现,以下是核心方法的 Go 实现。(1)Object.getClass():获取对象的类对象// 注册本地方法:java/lang/Object.getClass() func init() { native.Register("java/lang/Object", "getClass", "()Ljava/lang/Class;", getClass) } // getClass 实现:返回对象的类对象 func getClass(frame *rtda.Frame) { this := frame.LocalVars().GetThis() // 获取当前对象(this) class := this.Class().JClass() // 获取类对象(jClass 字段) frame.OperandStack().PushRef(class) // 推送类对象到操作数栈 }(2)Class.getName0():获取类的名称// 注册本地方法:java/lang/Class.getName0() func init() { native.Register("java/lang/Class", "getName0", "()Ljava/lang/String;", getName0) } // getName0 实现:返回类的全限定名 func getName0(frame *rtda.Frame) { this := frame.LocalVars().GetThis() // 获取 Class 实例(类对象) class := this.Extra().(*heap.Class) // 从 extra 字段获取 JVM 内部 Class 结构体 name := class.JavaName() // 转换类名为 Java 格式(如 "[I" → "int[]") jString := heap.JString(class.Loader(), name) // 转换为 Java String 对象 frame.OperandStack().PushRef(jString) // 推送结果到操作数栈 } // JavaName 将 JVM 类名转换为 Java 规范名称 func (c *Class) JavaName() string { if c.IsArray() { return c.name // 数组类名已符合规范(如 "[I") } return strings.ReplaceAll(c.name, "/", ".") // 普通类名:"java/lang/String" → "java.lang.String" }(3)Class.getPrimitiveClass():获取基本类型的类对象// 注册本地方法:java/lang/Class.getPrimitiveClass() func init() { native.Register("java/lang/Class", "getPrimitiveClass", "(Ljava/lang/String;)Ljava/lang/Class;", getPrimitiveClass) } // getPrimitiveClass 实现:返回基本类型的类对象 func getPrimitiveClass(frame *rtda.Frame) { vars := frame.LocalVars() nameObj := vars.GetRef(0) // 获取基本类型名称(如 "int") name := heap.GoString(nameObj) // 转换为 Go 字符串 loader := frame.Method().Class().Loader() var class *heap.Class switch name { case "void": class = loader.LoadClass("void") case "boolean": class = loader.LoadClass("boolean") // ... 其他基本类型 ... default: panic("Invalid primitive type: " + name) } frame.OperandStack().PushRef(class.JClass()) // 推送基本类型的类对象 }三、核心本地方法案例:数组拷贝与字符串操作除反射外,Java 类库中的许多基础功能依赖本地方法,如数组拷贝、字符串拼接等。以下实现关键场景的本地方法。1. System.arraycopy():数组拷贝// 注册本地方法:java/lang/System.arraycopy() func init() { native.Register("java/lang/System", "arraycopy", "(Ljava/lang/Object;ILjava/lang/Object;II)V", arraycopy) } // arraycopy 实现:数组元素拷贝 func arraycopy(frame *rtda.Frame) { vars := frame.LocalVars() src := vars.GetRef(0) // 源数组 srcPos := vars.GetInt(1) // 源数组起始位置 dest := vars.GetRef(2) // 目标数组 destPos := vars.GetInt(3)// 目标数组起始位置 length := vars.GetInt(4) // 拷贝长度 // 校验:源/目标数组非空 if src == nil || dest == nil { panic("java.lang.NullPointerException") } // 校验:数组类型兼容 if !checkArrayCopy(src, dest) { panic("java.lang.ArrayStoreException") } // 校验:索引不越界 if srcPos < 0 || destPos < 0 || length < 0 || srcPos+length > src.ArrayLength() || destPos+length > dest.ArrayLength() { panic("java.lang.IndexOutOfBoundsException") } // 执行拷贝(根据数组类型调用对应拷贝逻辑) heap.ArrayCopy(src, dest, srcPos, destPos, length) } // 校验数组拷贝的类型兼容性 func checkArrayCopy(src, dest *heap.Object) bool { srcClass, destClass := src.Class(), dest.Class() // 必须都是数组 if !srcClass.IsArray() || !destClass.IsArray() { return false } // 基本类型数组必须类型相同;引用类型数组允许子类向父类拷贝 if srcClass.ComponentClass().IsPrimitive() || destClass.ComponentClass().IsPrimitive() { return srcClass == destClass // 基本类型数组必须同类型 } return true // 引用类型数组兼容 }2. 字符串拼接与 String.intern()字符串拼接依赖 StringBuilder.append(),而 append 又依赖 System.arraycopy;String.intern() 则依赖字符串池实现常量共享。(1)String.intern():字符串驻留// 注册本地方法:java/lang/String.intern() func init() { native.Register("java/lang/String", "intern", "()Ljava/lang/String;", intern) } // intern 实现:将字符串驻留到字符串池 func intern(frame *rtda.Frame) { this := frame.LocalVars().GetThis() // 当前 String 对象 interned := heap.InternString(this) // 从字符串池获取驻留的字符串 frame.OperandStack().PushRef(interned) // 推送结果 } // InternString 实现字符串驻留 func InternString(jStr *Object) *Object { goStr := GoString(jStr) // 从 String 对象获取 Go 字符串 // 检查字符串池,存在则返回,否则添加 if interned, ok := internedStrings[goStr]; ok { return interned } internedStrings[goStr] = jStr return jStr }四、功能测试通过测试案例验证本地方法和反射机制的正确性。1. 反射测试:ClassTest 验证类名获取测试目标:通过反射获取基本类型、数组、普通类的类名。public class ClassTest { public static void main(String[] args) { System.out.println(void.class.getName()); // void System.out.println(boolean.class.getName()); // boolean System.out.println(int[].class.getName()); // [I System.out.println(Object.class.getName()); // java.lang.Object System.out.println("abc".getClass().getName()); // java.lang.String } }测试结果:正确输出各类的规范名称,验证 getClass()、getName0() 等本地方法正常工作。2. 字符串测试:StrTest 验证 intern() 机制测试目标:验证字符串池的驻留机制(intern() 后相同内容字符串引用相同)。public class StrTest { public static void main(String[] args) { String s1 = "abc1"; String s2 = "abc1"; System.out.println(s1 == s2); // true(常量池相同引用) int x = 1; String s3 = "abc" + x; // 动态拼接,初始不在常量池 System.out.println(s1 == s3); // false s3 = s3.intern(); // 驻留到字符串池 System.out.println(s1 == s3); // true(引用相同) } }测试结果:输出符合预期,验证 intern() 方法和字符串池机制正确。本章小结本章实现了本地方法调用和反射机制的核心逻辑,重点包括:本地方法框架:通过注册表(map)管理本地方法,注入伪字节码支持解释器流程,实现 invokenative 指令调用逻辑;反射机制:绑定类对象(java/lang/Class 实例)与类元信息,实现 getClass()、getName0() 等核心反射本地方法;关键本地方法:实现 System.arraycopy()(数组拷贝)、String.intern()(字符串驻留)等类库依赖的本地方法;功能验证:通过反射类名测试和字符串驻留测试,验证本地方法和反射机制的正确性。本地方法和反射是 Java 灵活性的重要支撑,下一章将完善异常处理机制,使 JVM 能更健壮地处理运行时错误。源码地址:https://github.com/Jucunqi/jvmgo.git
-
自己动手写 Java 虚拟机笔记 - 第八部分:数组与字符串的实现 前言在前一章中,我们实现了方法调用与返回机制,支撑了函数执行的核心流程。本章将聚焦 JVM 中数组和字符串的实现—— 这两类数据结构在 Java 中使用频繁,但它们的创建、存储和操作逻辑与普通对象存在显著差异。数组类由 JVM 运行时动态生成,而非从 Class 文件加载;字符串则通过常量池和字符串池实现共享。本章将详细实现这些特性,完善 JVM 对复杂数据结构的支持。参考资料《自己动手写 Java 虚拟机》—— 张秀宏开发环境工具 / 环境版本说明操作系统MacOS 15.5基于 Intel/Apple Silicon 均可JDK1.8用于字节码分析和测试Go 语言1.23.10项目开发主语言第八章:数组与字符串的核心实现数组和字符串是 Java 中最基础的数据结构,但其底层实现逻辑与普通对象不同。数组类由 JVM 动态生成,支持多维度和多种数据类型;字符串则通过常量池和字符串池实现高效存储和共享。本章将从数据结构设计、指令实现到功能测试,完整覆盖这两类结构的核心机制。一、数组概述:与普通类的本质区别数组是一种特殊的引用类型,其类信息并非来自 Class 文件,而是由 JVM 在运行时动态创建。理解数组与普通类的区别是实现的基础。特性普通类数组类类信息来源从 Class 文件加载由 JVM 运行时动态生成创建指令new 指令 + 构造器初始化newarray/anewarray/multianewarray 指令类名格式全限定名(如 java/lang/String)特殊格式(如 [I 表示 int 数组,[[Ljava/lang/Object; 表示二维对象数组)继承关系显式继承父类隐式继承 java/lang/Object,实现 Cloneable 和 Serializable 接口核心差异:数组类的结构由 JVM 动态定义,无需预编译的 Class 文件;其创建和操作依赖专门的指令,而非普通对象的 new 指令和构造器。二、数组的核心实现1. 数组对象的数据结构数组对象仍复用 Object 结构体,但通过 interface{} 字段存储数组元素(支持不同类型的数组数据):// Object 统一表示普通对象和数组对象 type Object struct { class *Class // 所属的类(数组类或普通类) data interface{} // 存储数据:普通对象存字段槽位,数组存元素集合 }设计说明:对于普通对象,data 字段存储实例变量的槽位数组(Slots);对于数组对象,data 字段存储 Go 切片(如 []int32 对应 int 数组,[]*Object 对应对象数组),通过 interface{} 兼容不同类型的数组元素。2. 数组类的动态生成数组类由 JVM 动态创建,无需加载 Class 文件。其类信息(如名称、继承关系)由 JVM 按固定规则生成:// NewArray 创建数组对象(根据数组类和长度初始化元素) func (c *Class) NewArray(count uint) *Object { if !c.IsArray() { panic("Not array class: " + c.name) // 校验是否为数组类 } // 根据数组类名创建对应类型的 Go 切片(映射 Java 数组类型) switch c.Name() { case "[Z": // boolean 数组 return &Object{class: c, data: make([]int8, count)} // boolean 用 int8 存储 case "[B": // byte 数组 return &Object{class: c, data: make([]int8, count)} case "[C": // char 数组 return &Object{class: c, data: make([]uint16, count)} // char 用 uint16 存储 case "[S": // short 数组 return &Object{class: c, data: make([]int16, count)} case "[I": // int 数组 return &Object{class: c, data: make([]int32, count)} case "[J": // long 数组 return &Object{class: c, data: make([]int64, count)} case "[F": // float 数组 return &Object{class: c, data: make([]float32, count)} case "[D": // double 数组 return &Object{class: c, data: make([]float64, count)} default: // 对象数组(如 [Ljava/lang/Object;) return &Object{class: c, data: make([]*Object, count)} } }类型映射规则:Java 数组类型与 Go 切片类型的映射需严格对应,确保元素存储和操作的正确性(如 boolean 数组在 JVM 中实际用 byte 存储,故映射为 []int8)。3. 数组类的加载逻辑数组类的加载由类加载器特殊处理,无需读取 Class 文件,直接动态生成类信息:// LoadClass 加载类(支持普通类和数组类) func (c *ClassLoader) LoadClass(name string) *Class { // 1. 检查缓存,已加载则直接返回 if class, ok := c.classMap[name]; ok { return class } // 2. 若为数组类,动态生成类信息 if name[0] == '[' { return c.loadArrayClass(name) } // 3. 加载普通类(从 Class 文件读取) return c.loadNonArrayClass(name) } // loadArrayClass 动态生成数组类信息 func (c *ClassLoader) loadArrayClass(name string) *Class { // 构建数组类的基本信息 class := &Class{ accessFlags: ACC_PUBLIC, // 数组类默认为 public name: name, // 数组类名(如 "[I") loader: c, // 类加载器 initStarted: true, // 数组类无需初始化 superClass: c.LoadClass("java/lang/Object"), // 继承 Object interfaces: []*Class{ // 实现 Cloneable 和 Serializable 接口 c.LoadClass("java/lang/Cloneable"), c.LoadClass("java/io/Serializable"), }, } c.classMap[name] = class // 存入缓存 return class }关键逻辑:数组类的继承和接口实现是固定的(继承 Object,实现 Cloneable 和 Serializable),无需像普通类那样从 Class 文件解析。三、数组操作指令实现JVM 提供专门的指令用于数组的创建、长度获取和元素访问,以下是核心指令的实现。1. newarray:创建基本类型数组用于创建基本类型的一维数组(如 int[]、float[]),操作数包括基本类型标识和数组长度。// 基本类型与 atype 对应关系(JVM 规范定义) const ( AT_BOOLEAN = 4 // boolean 数组 AT_CHAR = 5 // char 数组 AT_FLOAT = 6 // float 数组 AT_DOUBLE = 7 // double 数组 AT_BYTE = 8 // byte 数组 AT_SHORT = 9 // short 数组 AT_INT = 10 // int 数组 AT_LONG = 11 // long 数组 ) // NEW_ARRAY 创建基本类型数组 type NEW_ARRAY struct { atype uint8 // 基本类型标识(对应上述常量) } // 从字节码读取 atype 操作数 func (n *NEW_ARRAY) FetchOperands(reader *base.BytecodeReader) { n.atype = reader.ReadUint8() } // 执行指令:创建数组并推送引用到操作数栈 func (n *NEW_ARRAY) Execute(frame *rtda.Frame) { stack := frame.OperandStack() // 1. 从操作数栈弹出数组长度(必须非负) count := stack.PopInt() if count < 0 { panic("java.lang.NegativeArraySizeException") } // 2. 获取类加载器,解析数组类 classLoader := frame.Method().Class().Loader() arrClass := getPrimitiveArrayClass(classLoader, n.atype) // 3. 创建数组对象并推送引用到栈顶 arr := arrClass.NewArray(uint(count)) stack.PushRef(arr) } // 根据 atype 获取对应的数组类 func getPrimitiveArrayClass(loader *heap.ClassLoader, atype uint8) *heap.Class { switch atype { case AT_BOOLEAN: return loader.LoadClass("[Z") // boolean 数组类名为 "[Z" case AT_BYTE: return loader.LoadClass("[B") // byte 数组类名为 "[B" // 省略其他类型映射... default: panic("Invalid atype!") } }执行流程:从操作数栈获取数组长度并校验非负;根据 atype 确定数组类型(如 AT_INT 对应 [I 类);创建数组对象并将引用推送回操作数栈。2. anewarray:创建引用类型数组用于创建引用类型的一维数组(如 String[]、Object[]),操作数包括类符号引用索引和数组长度。// ANEW_ARRAY 创建引用类型数组 type ANEW_ARRAY struct { base.Index16Instruction // 包含常量池索引(指向类符号引用) } func (a *ANEW_ARRAY) Execute(frame *rtda.Frame) { cp := frame.Method().Class().ConstantPool() // 1. 解析类符号引用,获取元素类型 classRef := cp.GetConstant(a.Index).(*heap.ClassRef) componentClass := classRef.ResolveClass() // 如 "java/lang/String" // 2. 从操作数栈弹出数组长度并校验 stack := frame.OperandStack() count := stack.PopInt() if count < 0 { panic("java.lang.NegativeArraySizeException") } // 3. 获取数组类(元素类型的数组类,如 "[Ljava/lang/String;") arrClass := componentClass.ArrayClass() // 4. 创建数组对象并推送引用 arr := arrClass.NewArray(uint(count)) stack.PushRef(arr) } // ArrayClass 获取元素类型对应的数组类 func (c *Class) ArrayClass() *Class { arrClassName := "[" + c.name // 数组类名规则:元素类名前加 "[" return c.loader.LoadClass(arrClassName) }关键区别:与 newarray 不同,anewarray 需要先解析类符号引用获取元素类型,再动态生成数组类(如元素类型为 String 时,数组类为 [Ljava/lang/String;)。3. arraylength:获取数组长度用于获取数组的长度,无显式操作数,仅需数组引用。// ARRAY_LENGTH 获取数组长度 type ARRAY_LENGTH struct { base.NoOperandsInstruction } func (a *ARRAY_LENGTH) Execute(frame *rtda.Frame) { stack := frame.OperandStack() // 1. 从栈顶弹出数组引用并校验非空 arrRef := stack.PopRef() if arrRef == nil { panic("java.lang.NullPointerException") } // 2. 获取数组长度并推送回栈顶 length := arrRef.ArrayLength() stack.PushInt(length) } // ArrayLength 计算数组长度(根据数组类型返回对应切片长度) func (o *Object) ArrayLength() int32 { switch o.data.(type) { case []int8: return int32(len(o.data.([]int8))) case []uint16: return int32(len(o.data.([]uint16))) case []int32: return int32(len(o.data.([]int32))) // 省略其他类型... case []*Object: return int32(len(o.data.([]*Object))) default: panic("Not array!") } }实现逻辑:数组长度本质是底层 Go 切片的长度,通过类型断言获取不同切片的长度并返回。4. 数组元素访问指令:<t>aload 和 <t>astore<t>aload:从数组指定索引加载元素到操作数栈(如 iaload 加载 int 元素,aaload 加载引用元素);<t>astore:将操作数栈顶元素存入数组指定索引(如 iastore 存储 int 元素,aastore 存储引用元素)。以 aaload(引用元素加载)和 iastore(int 元素存储)为例:// AALOAD 从引用数组加载元素 func (a *AALOAD) Execute(frame *rtda.Frame) { stack := frame.OperandStack() // 1. 弹出索引和数组引用 index := stack.PopInt() arrRef := stack.PopRef() // 2. 校验非空和索引越界 checkNotNil(arrRef) refs := arrRef.Refs() // 获取引用数组([]*Object) checkIndex(len(refs), index) // 3. 推送元素到栈顶 stack.PushRef(refs[index]) } // IASTORE 向 int 数组存储元素 func (i *IASTORE) Execute(frame *rtda.Frame) { stack := frame.OperandStack() // 1. 弹出值、索引和数组引用 val := stack.PopInt() index := stack.PopInt() arrRef := stack.PopRef() // 2. 校验非空和索引越界 checkNotNil(arrRef) ints := arrRef.Ints() // 获取 int 数组([]int32) checkIndex(len(ints), index) // 3. 存储元素 ints[index] = val } // 辅助函数:校验数组非空 func checkNotNil(ref *heap.Object) { if ref == nil { panic("java.lang.NullPointerException") } } // 辅助函数:校验索引不越界 func checkIndex(arrLen int, index int32) { if index < 0 || index >= int32(arrLen) { panic("java.lang.ArrayIndexOutOfBoundsException") } }通用逻辑:所有元素访问指令均需先校验数组非空和索引合法性,再执行加载或存储操作,区别仅在于元素类型的处理。四、字符串的实现Java 字符串通过 java/lang/String 类表示,其核心是字符数组的封装,且通过字符串池实现常量字符串的共享。1. 字符串的本质:字符数组的封装String 类的核心字段是 value(字符数组,存储字符串内容)和 hash(缓存哈希值),JVM 中通过对象字段模拟这一结构:// Java 中的 String 类简化结构 public final class String { private final char value[]; // 存储字符串内容 private int hash; // 缓存哈希值(默认 0) // ... 构造器和方法 ... }在 JVM 实现中,字符串对象的 data 字段存储字符数组的引用,通过字段访问指令操作 value 数组。2. 字符串池:常量字符串的共享机制为节省内存,JVM 对字符串常量采用 “驻留” 机制 —— 相同内容的字符串常量在字符串池中仅存储一份,通过 intern() 方法实现共享。// 字符串池:key 为 Go 字符串(内容),value 为 Java String 对象 var internedStrings = map[string]*Object{} // JString 将 Go 字符串转换为 Java String 对象(并驻留到字符串池) func JString(loader *ClassLoader, goStr string) *Object { // 1. 检查字符串池,若已存在则直接返回 if internedStr, ok := internedStrings[goStr]; ok { return internedStr } // 2. 将 Go 字符串转换为 char 数组([]uint16) chars := stringToUtf16(goStr) // 3. 创建 char 数组对象("[C" 类) jChars := &Object{loader.LoadClass("[C"), chars} // 4. 创建 String 对象("java/lang/String" 类) jStrClass := loader.LoadClass("java/lang/String") jStr := jStrClass.NewObject() // 5. 为 String 对象的 "value" 字段赋值(字符数组) jStr.SetRefVar("value", "[C", jChars) // 6. 存入字符串池 internedStrings[goStr] = jStr return jStr } // stringToUtf16 将 Go 字符串转换为 UTF-16 编码的 char 数组([]uint16) func stringToUtf16(s string) []uint16 { runes := []rune(s) // 转换为 Unicode 码点 chars := make([]uint16, len(runes)) for i, r := range runes { chars[i] = uint16(r) } return chars }核心逻辑:字符串池通过 Go map 实现,键为字符串内容,值为对应的 String 对象;当创建字符串时,先检查池中有否相同内容的字符串,若有则复用,否则创建新对象并加入池。五、功能测试1. 数组测试:冒泡排序验证数组指令通过冒泡排序算法验证数组的创建、元素访问和修改指令的正确性:// 测试类:冒泡排序 public class BubbleSortTest { public static void main(String[] args) { int[] arr = {22, 84, 77, 56, 10, 43, 59}; int[] ints = bubbleSort(arr); for (int anInt : ints) { System.out.println(anInt); // 输出排序结果:10 22 43 56 59 77 84 } } public static int[] bubbleSort(int[] arr) { boolean swapped = true; int j = 0; int tmp; while (swapped) { swapped = false; j++; for (int i = 0; i < arr.length - j; i++) { if (arr[i] > arr[i + 1]) { tmp = arr[i]; arr[i] = arr[i + 1]; arr[i + 1] = tmp; swapped = true; } } } return arr; } }测试结果:排序后的数组元素按从小到大输出,验证 newarray、iaload、iastore、arraylength 等指令正常工作。2. 字符串测试:Hello World 验证字符串池通过经典的 Hello World 程序验证字符串创建和输出功能:// 测试类:输出 Hello World public class HelloWorld { public static void main(String[] args) { System.out.println("Hello World"); // 输出字符串 } }测试结果:成功输出 Hello World,验证字符串池、字符数组封装及 println 方法调用的正确性。本章小结本章实现了 JVM 中数组和字符串的核心机制,重点包括:数组的特殊实现:数组类由 JVM 动态生成,通过 interface{} 存储不同类型的数组元素,支持基本类型和引用类型数组;数组指令集:实现 newarray/anewarray(创建数组)、arraylength(获取长度)、<t>aload/<t>astore(元素访问)等指令,覆盖数组操作全流程;字符串机制:通过 java/lang/String 类封装字符数组,利用字符串池实现常量字符串的共享,减少内存占用;功能验证:通过冒泡排序和 Hello World 程序验证数组指令和字符串功能的正确性。数组和字符串的支持是 JVM 功能完整性的重要标志,下一章将讲述本地方法调用与反射的核心机制。源码地址:https://github.com/Jucunqi/jvmgo.git